
从今天开始,又一届世界杯赛事正式拉开帷幕,全世界的球迷与非球迷也将共同享受这段激情燃烧、热血澎湃的美好时光。清爽的啤酒已斟满、闪亮的屏幕已 就绪,每个人胸怀对国家的热爱以及也许有些不切实际的期盼关注着绿茵场上的竞逐。目前关于本届世界杯的各项统计数据已经火热出炉;巴西预计将迎来全球各地 共计370万名观众,由此带来的经济效应高达30.3亿美元;专门销售球星卡等周边产品的帕尼尼公司预计单在巴西本土,由贴纸带来的营收就将高达8910 万英镑;而在英国,达美乐披萨估计世界杯期间其销售总额也将达到8400万英镑。
不过关于某个重要话题,相关统计结果与数字似乎较为稀缺,这就是——谁能成为本届世界杯的最后赢家。我们可以估算出有多少球迷会亲身赶赴巴西,多少 英国人会在电视机前大嚼美好的披萨,又有多少狂热粉丝收集球星卡;但我们能否利用数据来预测谁会最终夺冠?为了避免有失偏颇,我们将一边了解怀疑论者的观 点、一边感受高盛集团等支持者对于数据驱动模型能够成功预测世界杯冠军归属的坚定决心。
怀疑论者:不,这不可能

左侧球员为被换上场的弗拉米尼
简而言之,足球是一项充满挑战的运动,我们很难利用分析手段准确预测其结果。正如《经济学家》去年在报道中所言,要在足球领域应用“魔球理论”绝非 易事。相对于棒球中那些更易衡量的离散事件,足球运动场上的二十二位参与者需要不断移动并以无穷无尽的方式组合彼此作用。足球天然具有动态属性,这就让判 断哪些因素需要考量并不断获取考量结果变得极具挑战。
尽管难度极高,但这一切并非不可能;我们最近曾报道过同样充满动态要素的篮球运动,目前摄像系统已经能够破解复杂的数据、告知参赛队伍的教练员篮球 以及球员在场上的具体位置——其精确程度甚至达到每个赛季每场比赛中的每一秒钟。类似的分析方式在足球领域同样行得通;ProZone以及Opta等企业 已经开始追踪运动场上的一系列指标——包括比赛中运动员的位置、传球的方式以及进球机会等等。一般来说,每场比赛产生的数据事件约有2000个。
不过这些数据的相对价值仍然有待观察。球队管理者在依靠原始数据进行球员选择时,既有成功的案例、也遇到过失败的状况。首先来看成功案例:阿森纳队 主教练温格注意到了弗拉米尼在比赛中出色的全场跑动距离以及优秀的临场表现,并最终决定用他取代维埃拉。不过失败的状况同样存在:弗格森通过数据认定斯坦 姆目前的抢断次数已经大不如前,并决意将其淘汰出队。然而后期数据显示,斯坦姆在意大利队用卓越表现证明了自己的价值。
问题的核心在于,尽管数据能够说明哪些球员在赛场上奔跑速度最快或者跑动距离最长、谁的抢断次数最多,但一位优秀的足球运动员并不仅仅是几项数值的简单累加。数据所反映的是过去,而并不足以证明球员未来的临场表现仍将延续目前的综合指标结论。
科学家:是的,我们可以
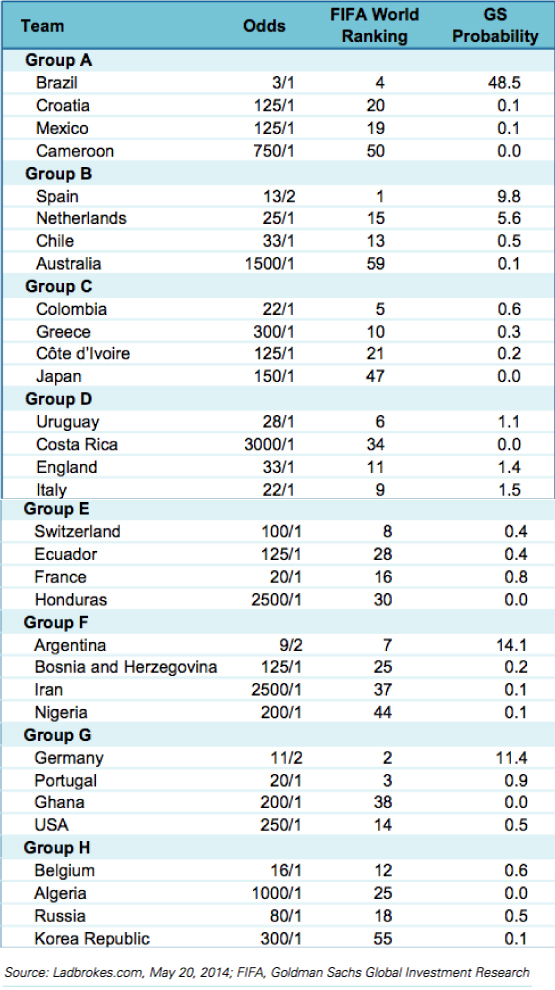
在对世界杯赛事结果进行预测时,高盛集团明智地回避了球员特定属性这一棘手的分析角度,转而采取更具通行性的办法。他们观察各支国家队在历届世界杯上的表现及其目前的Elo(即竞赛水平数值)排名情况,并借此制定出一套预测模型。他们对自己的方法作出了如下解释:
每场赛事的结果预测都基于一套完整的回归分析方案,并采用自1960年以来全 部正式国际比赛——也就是说不包括友谊赛——结果作为参考信息。这为我们带来约14000条预测指标,用以评估我们所使用的模型计算系数。在回归分析当 中,因变量为每周比赛参赛双方的进球数量。根据文献对足球比赛进行模型化归纳后,我们假定特定球队在匹配特定对手时的进球数量遵循以下泊松分布(一种常见 的离散概率分布)。
他们的这套模型发现巴西队拥有惊人的对阵胜出率——48.5%。他们预计巴西将在决赛中以3比1击败阿根廷队,而阿根廷方面的胜率仅为14.1%。 巴西队之所以能够获得如此高的评价,其因素可谓多种多样,其中包括出色的Elo系统排名、在世界杯赛场上相对于其它赛事更为强劲的实际表现以及今年的东道 主优势——自1930年以来,全部世界杯比赛中主办国队伍拿下大力神杯的比例高达30%。根据这套模型的推算,今年巴西在自家门前夺取冠军的机率高达 65%;相比之下欧洲各劲旅的日子就不太好过了,历史记录显示他们从未在美洲诸国主办的世界杯上获得过最终胜利。
不过这套模型完全依赖于过去的参考指标,显然无法反映未来可能出现的不确定因素。高盛集团曾经利用类似的分析模型以此前的表现为基础对英国在 2012年伦敦奥运会上的表现作出过预测。他们预计英国将拿下30枚金牌与总计65枚奖牌,而事实上英国最终夺得29枚金牌与总计65枚奖牌。
史蒂芬•霍金则采取另一种完全不同的分析方式得出了迥异于高盛的预测结论,他在考量了大量数据后认为英国今年最具夺冠潜力。在高盛的计算模型中,英 国今年的表现将令人失望、甚至无法从小组赛中出线,看来英国队最好是采信霍金的结论、以免士气低落。在进一步建议中,霍金认为英国采取4-3-3阵形最能 发挥自身实力,而比赛时间最好选在格林威治标准时间下午三点左右,并尽可能选派光头或者金发球员上场(因为这类球员的得分机率更高)。除此之外,他还建议 罚任意球或者点球的运动员采取三步以上的助跑距离并用侧脚踢球(这种方式能让得分机率提高10%),并尽量让皮球的落点在球门的左上或者右上角(这一区域 的进球成功率高达84%)。不过霍金也承认,这已经是数据在足球运动中所能给出的全部指导意见了。毕竟在实际罚球当中,英格兰队的表现一直相当糟糕。
说了这么多,大数据到底能否帮助我们预测世界杯的比赛结果?获得答案的惟一办法就是持续关注未来的一系列赛事,看看巴西能不能在占尽天时地利的情况下成功登顶。当然了,各位也不妨留心一下英格兰队能否在其向来令人捉鸡的点球大战中有所突破。
(原文地址)
 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,坦白说HDFS是一个不错的分布式文件系统,它有很多的优点,但也存在有一些缺点,包括:不适合低延迟数据访问、无法高效存储大量小文件、不支持多用户写入及任意修改文件。
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,坦白说HDFS是一个不错的分布式文件系统,它有很多的优点,但也存在有一些缺点,包括:不适合低延迟数据访问、无法高效存储大量小文件、不支持多用户写入及任意修改文件。






