Python编写CGI脚本是如何来实现的呢?下面的内容将会通过具体的实例来演示Python编写CGI脚本的实现方法及相关技巧:
你是否想使用Python语言创建一个网页,或者处理用户从web表单输入的数据?这些任务可以通过Python CGI(公用网关接口)脚本以及一个Apache web服务器实现。当用户请求一个指定URL或者和网页交互(比如点击””提交”按钮)的时候,CGI脚本就会被web服务器启用。CGI脚本调用执行完毕后,它的输出结果就会被web服务器用来创建显示给用户的网页。
配置Apache web服务器,让其能运行CGI脚本
在这个教程里,我们假设Apache web服务器已经安装好,并已运行。这篇教程使用的Apache web服务器(版本2.2.15,用于CentOS发行版6.5)运行在本地主机(127.0.0.1),并且监听80端口,如下面的Apache指令指定一样:
ServerName 127.0.0.1:80
Listen 80
下面举例中的HTML文件存放在web服务器上的/var/www/html目录下,并通过DocumentRoot指令指定(指定网页文件所在目录):
DocumentRoot "/var/www/html"
现在尝试请求URL:http://localhost/page1.html
这将返回web服务器中下面文件的内容:
/var/www/html/page1.html
为了启用CGI脚本,我们必须指定CGI脚本在web服务器上的位置,需要用到ScriptAlias指令:
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
以上指令表明CGI脚本保存在web服务器的/var/www/cgi-bin目录,请求URL里包含/cgi-bin/的将会搜索这个目录下的CGI脚本。
我们必须还要明确CGI脚本在/var/www/cgi-bin目录下有执行权限,还要指定CGI脚本的文件扩展名。使用下面的指令:
<directory "/var/www/cgi-bin">
Options +ExecCGI
AddHandler cgi-script .py
</directory>
下面访问URL:http://localhost/cgi-bin/myscript-1.py
这将会调用web服务器中下面所示脚本:
/var/www/cgi-bin/myscript-1.py
创建一个CGI脚本
在创建一个Python CGI脚本之前,你需要确认你已经安装了Python(这通常是默认安装的,但是安装版本可能会有所不同)。本篇教程使用的脚本是使用Python版本2.6.6编写的。你可以通过下面任意一命令(-V和–version参数将显示所安装Python的版本号)检查Python的版本。
$ python -V
$ python --version
如果你的Python CGI脚本要用来处理用户输入的数据(从一个web输入表单),那么你将需要导入Python cgi模块。这个模块可以处理用户通过web输入表单输入的数据。你可以在你的脚本中通过下面的语句导入该脚本:
import cgi
你也必须修改Python CGI脚本的执行权限,以防止web服务器不能调用。可以通过下面的命令增加执行权限:
# chmod o+x myscript-1.py
Python CGI例子
涉及到Python CGI脚本的两个方案将会在下面讲述:
- 使用Python脚本创建一个网页
- 读取并显示用户输入的数据,并且在网页上显示结果
注意:Python cgi模块在方案2中是必需的,因为这涉及到用户从web表单输入数据。
例子1 :使用Python脚本创建一个网页
对于这个方案,我们将通过创建包含一个单一提交按钮的网页/var/www/html/page1.html开始。
<html>
<h1>Test Page 1</h1>
<form name="input" action="/cgi-bin/myscript-1.py" method="get">
<input type="submit" value="Submit">
</form>
</html>
当”提交”按钮被点击,/var/www/cgi-bin/myscript-1.py脚本将被调用(通过action参数指定)。通过设置方法参数为”get”来指定一个”GET”请求,服务器将会返回指定的网页。/var/www/html/page1.html在浏览器中的显示情况如下:
/var/www/cgi-bin/myscript-1.py的内容如下:
#!/usr/bin/python
print "Content-Type: text/html"
print ""
print "<html>"
print "<h2>CGI Script Output</h2>"
print "<p>This page was generated by a Python CGI script.</p>"
print "</html>"
第一行声明表示这是使用 /usr/bin/python命令运行的Python脚本。”Content-Type: text/html”打印语句是必需的,这是为了让web服务器知道接受自CGI脚本的输出类型。其余的语句用来输出HTML格式的其余网页内容。
当”Submit”按钮点击,下面的网页将返回:
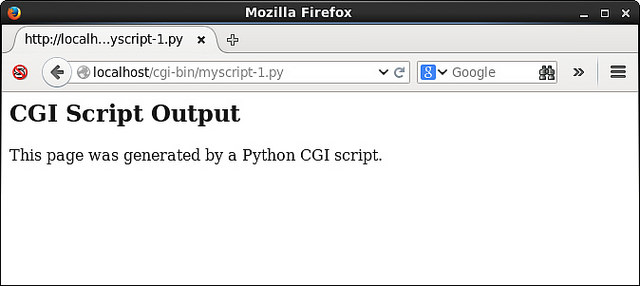
这个例子的要点是你可以决定哪些信息可以被CGI脚本返回。这可能包括日志文件的内容,当前登陆用户的列表,或者今天的日期。在你处理时拥有所有python库的可能性是无穷无尽的。
例子2:读取并显示用户输入的数据,并将结果显示在网页上
对于这个方案,我们将通过创建一个含有三个输入域和一个提交按钮的网页/var/www/html/page2.html开始。
<html>
<h1>Test Page 2</h1>
<form name="input" action="/cgi-bin/myscript-2.py" method="get">
First Name: <input type="text" name="firstName"><br />
Last Name: <input type="text" name="lastName"><br />
Position: <input type="text" name="position"><br />
<input type="submit" value="Submit">
</form>
</html>
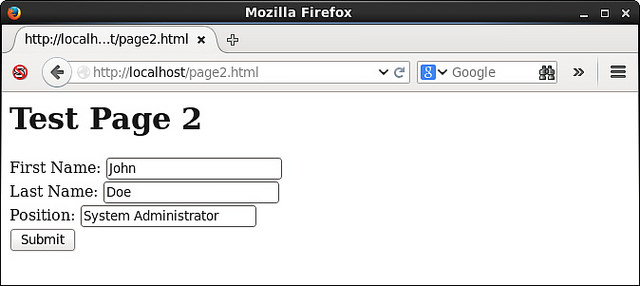
当”Submit”按钮点击,/var/www/cgi-bin/myscript-2.py脚本将被执行(通过action参数指定)。/var/www//html/page2.html显示在web浏览器中的图片如下所示(注意,三个输入域已经被填写好了):
/var/www/cgi-bin/myscript-2.py的内容如下:
#!/usr/bin/python
import cgi
form = cgi.FieldStorage()
print "Content-Type: text/html"
print ""
print "<html>"
print "<h2>CGI Script Output</h2>"
print "<p>"
print "The user entered data are:<br />"
print "<b>First Name:</b> " + form["firstName"].value + "<br />"
print "<b>Last Name:</b> " + form["lastName"].value + "<br />"
print "<b>Position:</b> " + form["position"].value + "<br />"
print "</p>"
print "</html>"
正如前面提到,import cgi语句用来确保能够处理用户通过web输入表单输入的数据。web输入表单被封装在一个表单对象中,叫做cgi.FieldStorage对象。一旦开始输出,”Content-Type: text/html”是必需的,因为web服务器需要知道接受自CGI脚本的输出格式。用户输入的数据在包含form[“firstName”].value,form[“lastName”].value,和 form[“position”].value的语句中可以得到。那些中括号中的名称和/var/www/html/page2.html文本输入域中定义的名称参数一致。
当网页上的”Submit”按钮被点击,下面的网页将被返回。
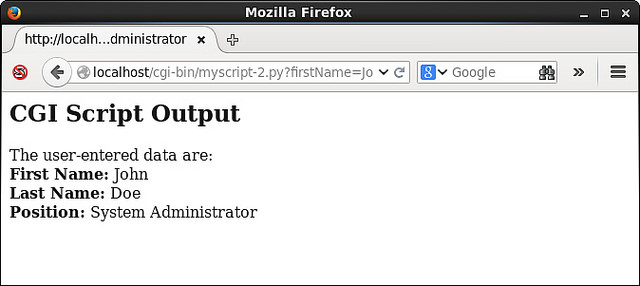
这个例子的要点就是你可以很容易地读取并显示用户在web表单上输入的数据。除了以字符串的方式处理数据,你也可以用Python将用户输入的数据转化为可用于数值计算的数字。
Python编写CGI脚本就是这样,欢迎大家参考。。。。
